
- 분류 전체보기 (413)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- java
- PostgreSQL
- analytics4
- spring
- pandas
- Javascript
- 명령어
- Linux
- SQL
- pem
- 리눅스
- IntelliJ
- oracle
- iBatis
- 호이스팅
- mssql
- DBMS
- mysql
- git
- 티스토리챌린지
- 오블완
- Python
- isNotEmpty
- isempty
- Kibana
- MongoDB
- 자바
- MariaDB
- docker
- github
- Today
- Total
hanker
Python - pandas 데이터 정렬하기 (sort_values() 옵션 파헤치기) 본문
pandas에서는 sort_values() 메서드를 사용하여 데이터를 원하는 기준에 따라 정렬할 수 있다.
이번 글에서는 sort_values() 메서드의 사용법을 알아보자.
1. sort_values()
pandas의 sort_values()는 특정 열(column)을 기준으로 데이터를 정렬할 때 사용된다.
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False)- by : 정렬 기준이 될 열(컬럼) 또는 여러 개의 열을 리스트로 지정
- axis : 0이면 행 기준 정렬(기본값) , 1이면 열 기준 정렬
- ascending : True 면 오름차순 (기본값), False 면 내림차순
- inplace : True 면 원본 데이터프레임이 변경된다. (기본값 False)
2. 단일 열 기준 정렬
열 기준으로 데이터 프레임을 정렬해보자.
import pandas as pd
# 샘플 데이터 생성
data = {
"product": ["Laptop", "Mouse", "Keyboard", "Monitor", "Tablet"],
"price": [1000, 50, 150, 300, 500]
}
df = pd.DataFrame(data)
# price 기준 오름차순 정렬
sorted_df = df.sort_values(by="price")
print(sorted_df)
price 기준 오름차순(작은 값 → 큰 값)으로 정렬되었다.
3. 내림차순 정렬
내림차순 정렬을 원한다면 ascending=False를 추가하면 된다.
import pandas as pd
# 샘플 데이터 생성
data = {
"product": ["Laptop", "Mouse", "Keyboard", "Monitor", "Tablet"],
"price": [1000, 50, 150, 300, 500]
}
df = pd.DataFrame(data)
# price기준 내림차순 정렬
sorted_df_desc = df.sort_values(by="price", ascending=False)
print(sorted_df_desc)
4. 여러 열 기준 정렬
정렬 기준이 여러 개인 경우, by 매개변수에 리스트를 전달하면 된다.
import pandas as pd
# 여러 열 기준 정렬
data = {
"product": ["Laptop", "Mouse", "Keyboard", "Monitor", "Tablet"],
"price": [1000, 50, 150, 300, 500],
"rating": [4.5, 4.7, 4.5, 4.2, 4.7]
}
df = pd.DataFrame(data)
# price 오름차순 → rating 내림차순 정렬
sorted_df_multi = df.sort_values(by=["price", "rating"], ascending=[True, False])
print(sorted_df_multi)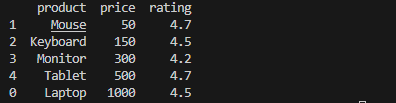
price 기준으로 먼저 오름차순을 정렬한 후, 동일한 price 값이 있을경우 rating 기준으로 내림차순 정렬한다.
5. 인덱스를 기준으로 정렬하기
인덱스를 기준으로 정렬하려면 sort_index()를 사용한다.
import pandas as pd
# 여러 열 기준 정렬
data = {
"product": ["Laptop", "Mouse", "Keyboard", "Monitor", "Tablet"],
"price": [1000, 50, 150, 300, 500],
"rating": [4.5, 4.7, 4.5, 4.2, 4.7]
}
df = pd.DataFrame(data)
# price 오름차순 → rating 내림차순 정렬
sorted_df_multi = df.sort_values(by=["price", "rating"], ascending=[True, False])
print(sorted_df_multi)
# Index 기준 내림차순
df_sorted_index = df.sort_index(ascending=False)
print(df_sorted_index)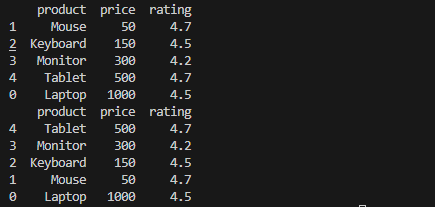
sort_index() 메서드를 사용하여 인덱스를 오름차순(기본값) 또는 내림차순으로 정렬할 수 있다.
6. 원본 데이터프레임 변경
정렬된 데이터를 새로운 변수에 저장하지 않고, 원본 데이터프레임을 직접 변경하려면 inplace =True 를 설정한다.
import pandas as pd
data = {
"product": ["Laptop", "Mouse", "Keyboard", "Monitor", "Tablet"],
"price": [1000, 50, 150, 300, 500],
"rating": [4.5, 4.7, 4.5, 4.2, 4.7]
}
df = pd.DataFrame(data)
df.sort_values(by="price", ascending=False, inplace=True)
print(df)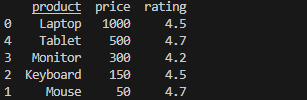
df 자체가 변경된 걸 확인할 수 있다.
7. NaN(결측값) 처리
sort_values()를 사용할 때 NaN(결측값)은 기본적으로 가장 마지막에 배치된다.
하지만 na_position 매개변수를 이용해 NaN을 맨 앞으로 정렬할 수도 있다.
import pandas as pd
# 여러 열 기준 정렬
data_with_nan = {
"product": ["Laptop", "Mouse", "Keyboard", "Monitor", "Tablet"],
"price": [1000, None, 150, 300, None]
}
df_nan = pd.DataFrame(data_with_nan)
# NaN을 앞으로 정렬
sorted_df_nan = df_nan.sort_values(by="price", na_position="first")
print(sorted_df_nan)
(기본값)na_position="last"이면 NaN 값이 맨 뒤로 빠지게 된다.
8. 정렬을 적용한 후 인덱스 재정렬
정렬 후에도 기존 인덱스가 유지되는데, 인덱스를 새롭게 설정하고 싶으면 ignore_index=True 옵션을 사용하면 된다.
import pandas as pd
data_with_nan = {
"product": ["Laptop", "Mouse", "Keyboard", "Monitor", "Tablet"],
"price": [1000, None, 150, 300, None]
}
df = pd.DataFrame(data_with_nan)
sorted_df = df.sort_values(by="price", ascending=True)
sorted_df_reset = df.sort_values(by="price", ascending=True, ignore_index=True)
print(sorted_df)
print(sorted_df_reset)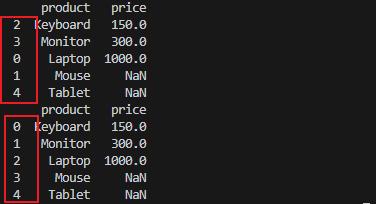
정리
Pandas의 sort_values()를 사용하면 데이터를 쉽게 정렬할 수 있다.
끝.
'Python' 카테고리의 다른 글
| python - pandas 문자열 변환 (0) | 2025.03.02 |
|---|---|
| pandas - drop_duplicates() (중복 데이터 제거하기) (0) | 2025.03.01 |
| Python - pandas 데이터 타입 변환 (0) | 2025.02.26 |
| Python - 결측치 (Missing Value) 처리 방법 (0) | 2025.02.23 |
| Python - Pandas를 활용한 데이터 분석 (설치 및 사용법) (0) | 2025.02.16 |



